写经管论文总被方法同质化困扰?想找一个既有技术含量、又能贴合经管场景的研究方法?
今天就给大家拆解一个「论文创新加分项」——机器学习中的强化学习方法。不用啃复杂公式,用通俗的语言讲清它的核心原理、优缺点,以及最关键的「经管论文应用场景」,帮你快速打开思路~
一、强化学习到底是什么?
强化学习问题涉及学习如何行动——如何将情境映射到行动——以最大化数值奖励信号。从本质上讲,它们是闭环问题,因为学习系统的行动会影响其后续的输入。此外,与许多机器学习形式不同,学习者不会被告知应该采取哪些行动,而是必须通过尝试来发现哪些行动能够带来最大的奖励。在最有趣和最具挑战性的案例中,行动不仅会影响即时奖励,还会影响下一个情境,进而影响所有后续奖励。这三个特点——本质上是闭环的,没有直接的行动指令,以及行动的后果(包括奖励信号)在较长时间内发挥作用——是强化学习问题的三个最重要的区别特征(Reinforcement Learning: An Introduction,Richard and Andrew 2014)。
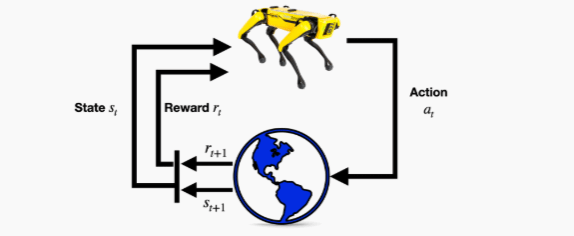
其实强化学习的逻辑特别好理解,类比我们平时“打怪升级”就够了:假设你是一个「智能体」(可以理解为做决策的主体,比如企业、消费者、管理者),身处一个「环境」(比如市场、供应链、金融市场)中,每做一个「动作」(比如定价、库存调整、投资决策),环境都会给你一个「反馈」(比如盈利增加、成本下降,这是正向奖励;或者亏损、库存积压,这是负向惩罚)。
强化学习的核心,就是让这个“智能体”在不断尝试中,学会「最优策略」——也就是能拿到最多“奖励”、避开“惩罚”的一系列决策,最终实现目标最大化(比如企业利润最大化、供应链效率最高、投资收益最优)。
和我们熟悉的监督学习(需要大量标注数据)不同,强化学习不需要提前告诉“智能体”“什么动作是对的”,而是让它自己在“试错”中学习,更贴合经管领域「动态决策」的特点——毕竟市场环境、消费者行为永远在变,没有固定的“标准答案”(Sutton R S, Barto A G., 1998)。
简单总结核心三要素:智能体(决策主体)、环境(决策场景)、奖励(决策反馈),三者联动,实现“试错-学习-优化”的闭环,这也是强化学习能适配经管场景的核心原因(Mnih V, Kavukcuoglu K, et al., 2015)。
二、客观看待:强化学习的优缺点
任何研究方法都有两面性,强化学习的优势和局限都很鲜明,写论文时重点突出这部分,能体现你的研究客观性,下面结合经管场景具体说:
✅ 核心优点(适配经管研究的3个关键优势)
1. 擅长动态决策,贴合经管实际:经管领域的决策大多不是“一劳永逸”的(比如企业定价要根据市场需求调整,供应链库存要应对需求波动),强化学习能实时捕捉环境变化,动态优化决策,比传统静态模型(比如线性回归)更具实用性。
2. 无需大量标注数据,降低研究门槛:很多经管研究面临“数据难获取、标注成本高”的问题(比如小众行业的决策数据),强化学习不需要提前标注“正确决策”,只要设定好“奖励规则”,就能通过模拟试错生成学习数据,尤其适合数据稀缺的场景。
3. 能实现长期目标优化:经管研究往往追求“长期利益最大化”(比如企业长期盈利、供应链长期稳定),强化学习不会只关注“当下的奖励”(比如短期低价促销的小收益),而是会权衡长期收益,贴合经管研究的核心诉求。
❌ 主要局限(论文中需规避或改进的点)
1. 样本效率低,训练成本较高:强化学习需要大量“试错”才能学会最优策略,尤其是复杂的经管场景(比如多主体竞争的市场),训练过程耗时较长,可能需要借助编程工具(比如Python)优化,对研究者的实操能力有一定要求。
2. 奖励函数设计难度大:“奖励”的设定直接影响学习效果,比如在供应链优化中,若只设定“成本最低”为奖励,可能会忽略缺货风险;若奖励规则太复杂,又会导致模型难以收敛,这需要研究者结合具体研究场景精准设计。
3. 可解释性较弱:和传统计量方法(比如OLS回归)相比,强化学习的决策过程更像“黑箱”——我们能得到最优决策,但很难清晰解释“为什么这个决策是最优的”,这也是当前经管研究中应用强化学习时,需要重点补充的部分。
三、重点来了:强化学习在经管论文中的4大应用场景
很多同学担心“强化学习太技术化,和经管研究脱节”,其实不然——它的核心是“决策优化”,而经管领域的核心就是“决策”,下面4个高频应用场景,附具体研究方向,帮你快速对接自己的论文:
场景1:供应链管理(最成熟、最易落地)
研究方向:库存优化、供应商选择、物流路径规划。
具体应用:比如用强化学习训练“库存决策智能体”,根据市场需求波动、补货周期、仓储成本等因素,自动调整库存水平,避免缺货或积压;或者优化供应商选择策略,在保证供货稳定的前提下,降低采购成本。
参考思路:可对比传统库存模型(如EOQ模型)与强化学习模型的优化效果,突出强化学习在动态需求下的优势.
场景2:金融与投资决策
研究方向:投资组合优化、量化交易、风险控制。
具体应用:比如用强化学习构建投资决策模型,根据股票、基金等资产的历史数据和实时市场行情,自动调整投资组合比例,实现“收益最大化、风险最小化”;或者用于量化交易策略的优化,捕捉市场短期波动中的盈利机会。
参考思路:可聚焦某一具体金融市场(如A股、基金市场),构建强化学习投资模型,与传统投资策略(如均值-方差模型)对比。
场景3:市场营销与定价策略
研究方向:动态定价、客户细分、营销策略优化。
具体应用:比如电商平台的动态定价——用强化学习根据用户画像、购买历史、市场竞争情况,实时调整商品价格,既保证销量,又最大化利润;或者优化营销策略,根据不同客户群体的反馈,调整广告投放、促销活动等策略。
参考思路:可结合某一具体行业(如电商、餐饮),设计强化学习动态定价模型,分析模型在不同市场环境下的表现。
场景4:企业管理与决策优化
研究方向:生产调度、人力资源配置、企业战略决策。
具体应用:比如制造企业的生产调度——用强化学习根据订单数量、生产设备状态、人力成本等因素,优化生产流程,提高生产效率;或者优化人力资源配置,根据员工能力、工作任务需求,合理分配岗位,降低人力成本。
参考思路:可选取某一制造企业或服务企业作为案例,构建强化学习决策模型,验证模型对企业效率、成本的优化效果,可结合Sutton等(1998)的经典教材,完善模型的理论基础。
四、参考文献
[1] Sutton, R. S., & Barto, A. G. (1998). Reinforcement learning: An introduction (Vol. 1, No. 1, pp. 9-11). Cambridge: MIT press.
[2] Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
[3] Nowak, M., & Pawłowska-Nowak, M. (2024). Dynamic pricing method in the e-commerce industry using machine learning. Applied Sciences, 14(24), 11668.
最后小结
强化学习不是“高大上的技术噱头”,而是适配经管研究“动态决策”需求的实用方法——它的核心优势是能应对复杂、多变的经管场景,解决传统方法难以处理的决策优化问题,而局限则可通过合理设计模型、结合传统计量方法来弥补。
对于经管论文来说,只要选对应用场景(比如供应链、金融),结合文中的参考文献和研究思路,就能快速搭建论文框架,实现方法创新。
如果还是不知道怎么结合自己的论文方向,不妨留言说说你的研究领域,帮你进一步拆解强化学习的应用思路~

